
After two decades of building and operating enterprise systems, I’ve watched the IT operations landscape transform dramatically. What started as siloed development and operations teams has evolved into a rich ecosystem of methodologies, each addressing specific organizational challenges. In this comprehensive guide, I’ll share my perspective on four dominant approaches: DevOps, DevSecOps, Site Reliability Engineering (SRE), and Platform Engineering—and help you understand when to apply each.
The Evolution of IT Operations
The traditional model of “developers build, operations run” created friction that slowed delivery and introduced reliability issues. Each methodology we’ll explore emerged to address specific pain points in this model, and understanding their origins helps clarify when each approach makes sense.
DevOps: Breaking Down Silos
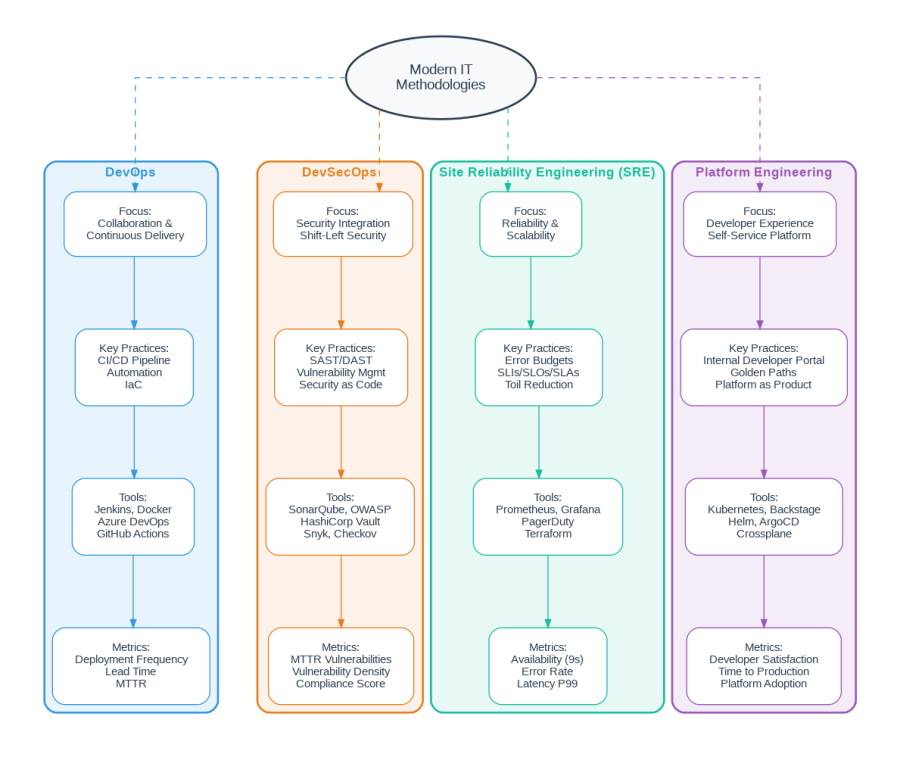
DevOps emerged around 2008-2009 as a cultural movement focused on collaboration between development and operations teams. At its core, DevOps is about breaking down organizational silos and creating shared responsibility for the entire software delivery lifecycle.
Core Principles: DevOps emphasizes continuous integration and continuous delivery (CI/CD), infrastructure as code, automated testing, and monitoring. The goal is to reduce the time between committing code and deploying it to production while maintaining quality and stability.
Key Practices: Teams implementing DevOps typically adopt version control for everything (including infrastructure), automated build and deployment pipelines, comprehensive monitoring and logging, and blameless post-mortems when incidents occur.
Tooling Ecosystem: Jenkins, GitHub Actions, GitLab CI/CD, Azure DevOps, Docker, Kubernetes, Terraform, Ansible, Prometheus, and Grafana form the backbone of most DevOps implementations.
Metrics That Matter: Deployment frequency, lead time for changes, mean time to recovery (MTTR), and change failure rate—the four DORA metrics—provide objective measures of DevOps effectiveness.
DevSecOps: Security as a First-Class Citizen
DevSecOps extends DevOps by integrating security practices throughout the software development lifecycle rather than treating security as an afterthought or a gate at the end of the process. The “shift-left” approach moves security considerations earlier in the development process.
Core Principles: Security is everyone’s responsibility, not just the security team’s. Automated security testing runs continuously, vulnerabilities are treated as bugs to be fixed immediately, and security policies are codified and version-controlled.
Key Practices: Static Application Security Testing (SAST) in the IDE and CI pipeline, Dynamic Application Security Testing (DAST) against running applications, Software Composition Analysis (SCA) for dependency vulnerabilities, Infrastructure as Code security scanning, and secrets management.
Tooling Ecosystem: SonarQube, Snyk, Checkmarx, OWASP ZAP, HashiCorp Vault, Checkov, Tfsec, Trivy, and Aqua Security represent the modern DevSecOps toolkit.
Metrics That Matter: Mean time to remediate vulnerabilities, vulnerability density per release, security debt ratio, and compliance score provide visibility into security posture.
Site Reliability Engineering (SRE): Reliability Through Engineering
SRE originated at Google in the early 2000s as a way to apply software engineering principles to operations problems. Rather than treating operations as a separate discipline, SRE treats reliability as a feature that can be engineered, measured, and improved systematically.
Core Principles: SRE introduces the concept of error budgets—the acceptable amount of unreliability based on Service Level Objectives (SLOs). When the error budget is healthy, teams can push features faster; when it’s depleted, reliability work takes priority. This creates a data-driven balance between velocity and stability.
Key Practices: Defining Service Level Indicators (SLIs) and SLOs, managing error budgets, eliminating toil through automation, conducting blameless post-mortems, and capacity planning based on data rather than intuition.
Tooling Ecosystem: Prometheus, Grafana, PagerDuty, Datadog, New Relic, Terraform, and custom tooling for SLO tracking and error budget management.
Metrics That Matter: Availability (measured in “nines”), error rate, latency percentiles (P50, P95, P99), and error budget consumption rate.
Platform Engineering: Developer Experience at Scale
Platform Engineering is the newest of these methodologies, emerging as organizations realized that expecting every development team to become infrastructure experts wasn’t scalable. Platform teams build Internal Developer Platforms (IDPs) that abstract infrastructure complexity and provide self-service capabilities.
Core Principles: Treat the platform as a product with developers as customers. Provide golden paths—opinionated, well-supported ways to accomplish common tasks—while still allowing flexibility for edge cases. Reduce cognitive load on development teams by handling infrastructure complexity centrally.
Key Practices: Building Internal Developer Portals (like Backstage), creating standardized templates and scaffolding, providing self-service infrastructure provisioning, maintaining documentation and developer guides, and measuring developer satisfaction and productivity.
Tooling Ecosystem: Backstage, Kubernetes, Helm, ArgoCD, Crossplane, Terraform, and custom portal development.
Metrics That Matter: Developer satisfaction scores, time to first deployment for new services, platform adoption rate, and support ticket volume.
When to Use What: A Decision Framework
Based on my experience implementing these methodologies across various organizations, here’s how I think about choosing the right approach:
Start with DevOps if you’re breaking down silos between development and operations for the first time, your deployment frequency is measured in weeks or months rather than days, or you lack automated CI/CD pipelines and infrastructure as code.
Add DevSecOps when you’re in a regulated industry (finance, healthcare, government), you’ve experienced security incidents or near-misses, security reviews are bottlenecking your release process, or you’re handling sensitive customer data.
Adopt SRE practices when reliability is a competitive differentiator for your product, you need objective ways to balance feature velocity with stability, your systems have grown complex enough that intuition-based operations no longer work, or you want to move from reactive firefighting to proactive reliability engineering.
Invest in Platform Engineering when you have more than 5-10 development teams, developers are spending significant time on infrastructure tasks, you’re seeing inconsistent practices across teams, or onboarding new developers takes weeks rather than days.
The Convergence: These Aren’t Mutually Exclusive
In practice, mature organizations often combine elements of all four approaches. A platform team might build an IDP that embeds DevSecOps practices into golden paths while using SRE principles to ensure the platform itself is reliable. The key is understanding which problems each methodology solves and applying them appropriately to your context.
The most successful implementations I’ve seen share common traits: they start with cultural change before tooling, they measure outcomes rather than activities, they iterate based on feedback, and they recognize that the goal is delivering value to customers—not implementing a methodology for its own sake.
Conclusion
Each of these methodologies represents hard-won lessons from organizations that faced similar challenges to yours. DevOps taught us that collaboration beats silos. DevSecOps showed us that security must be built in, not bolted on. SRE demonstrated that reliability can be engineered systematically. Platform Engineering proved that developer experience scales better than expecting everyone to be infrastructure experts.
The question isn’t which methodology is “best”—it’s which combination addresses your organization’s specific challenges. Start where you are, measure your progress, and evolve your practices as your needs change. That’s the real lesson these methodologies teach us: continuous improvement isn’t just for code—it’s for how we work together to deliver software.
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.