Introduction: LLM API costs can spiral quickly—a chatbot handling 10,000 daily users at $0.01 per conversation costs $3,000 monthly. Production systems need cost optimization without sacrificing quality. This guide covers practical strategies: semantic caching to avoid redundant calls, model routing to use cheaper models when possible, prompt compression to reduce token counts, and monitoring to catch cost anomalies early. These techniques can reduce costs by 50-80% while maintaining user experience.
- Part 1 (this article): Reducing API spend without sacrificing quality
- Part 2: Model routing, token reduction, and budget management
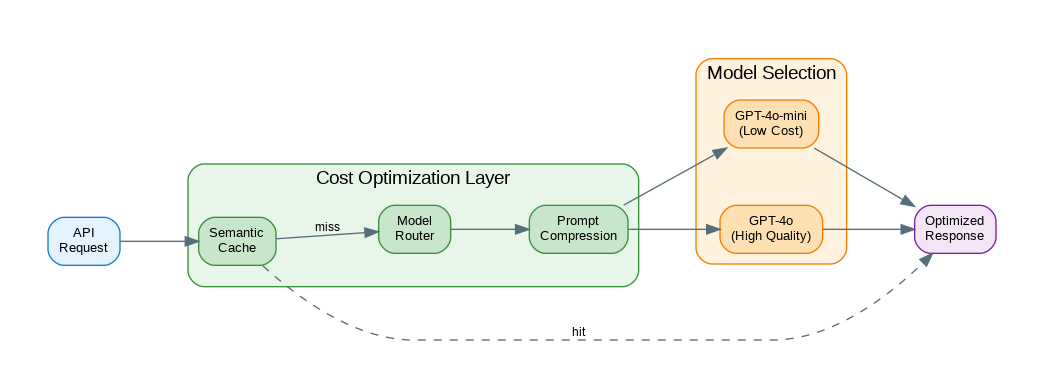
Cost Optimization Architecture
Effective cost management requires visibility, control, and optimization at every layer. This diagram shows the key components of a cost-optimized LLM system.
flowchart TB
subgraph Input["Request Processing"]
REQ[Request]
PC[Prompt Compressor]
TL[Token Limiter]
end
subgraph Cache["Caching Layer"]
SC[Semantic Cache]
VDB[(Vector DB)]
end
subgraph Routing["Smart Routing"]
CL[Complexity Classifier]
MR[Model Router]
end
subgraph Models["Model Tier"]
T1[Tier 1: GPT-4o-mini
$0.15/1M]
T2[Tier 2: GPT-4o
$5/1M]
T3[Tier 3: o1
$15/1M]
end
subgraph Monitor["Cost Monitoring"]
CT[Cost Tracker]
BM[Budget Manager]
AL[Alert System]
end
REQ --> PC
PC --> TL
TL --> SC
SC -->|Hit| REQ
SC -->|Miss| CL
CL --> MR
MR --> T1
MR --> T2
MR --> T3
T1 --> CT
T2 --> CT
T3 --> CT
CT --> BM
BM --> AL
style REQ fill:#E3F2FD,stroke:#90CAF9,stroke-width:2px,color:#1565C0
style PC fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style TL fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style SC fill:#F3E5F5,stroke:#CE93D8,stroke-width:2px,color:#6A1B9A
style VDB fill:#ECEFF1,stroke:#90A4AE,stroke-width:2px,color:#455A64
style CL fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style MR fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style T1 fill:#E8F5E9,stroke:#A5D6A7,stroke-width:2px,color:#2E7D32
style T2 fill:#FFF3E0,stroke:#FFCC80,stroke-width:2px,color:#E65100
style T3 fill:#FCE4EC,stroke:#F48FB1,stroke-width:2px,color:#AD1457
style CT fill:#E0F2F1,stroke:#80CBC4,stroke-width:2px,color:#00695C
style BM fill:#E0F2F1,stroke:#80CBC4,stroke-width:2px,color:#00695C
style AL fill:#E0F2F1,stroke:#80CBC4,stroke-width:2px,color:#00695C
Figure 1: C4 Container Diagram – Cost Optimization Architecture
Cost Tracking Foundation
The following code implements cost tracking foundation. Key aspects include proper error handling and clean separation of concerns.
from dataclasses import dataclass, field
from datetime import datetime, timedelta
from collections import defaultdict
import json
@dataclass
class ModelPricing:
input_per_1k: float
output_per_1k: float
cached_input_per_1k: float = 0.0 # For providers with prompt caching
PRICING = {
"gpt-4o": ModelPricing(0.0025, 0.01),
"gpt-4o-mini": ModelPricing(0.00015, 0.0006),
"gpt-4-turbo": ModelPricing(0.01, 0.03),
"gpt-3.5-turbo": ModelPricing(0.0005, 0.0015),
"claude-3-5-sonnet": ModelPricing(0.003, 0.015),
"claude-3-haiku": ModelPricing(0.00025, 0.00125),
}
@dataclass
class UsageRecord:
timestamp: datetime
model: str
input_tokens: int
output_tokens: int
cost: float
endpoint: str = ""
user_id: str = ""
class CostTracker:
"""Track and analyze LLM costs."""
def __init__(self):
self.records: list[UsageRecord] = []
self.daily_budget: float = 100.0
self.alert_threshold: float = 0.8
def record(
self,
model: str,
input_tokens: int,
output_tokens: int,
endpoint: str = "",
user_id: str = ""
) -> float:
"""Record usage and return cost."""
pricing = PRICING.get(model, ModelPricing(0.01, 0.03))
cost = (
(input_tokens / 1000) * pricing.input_per_1k +
(output_tokens / 1000) * pricing.output_per_1k
)
record = UsageRecord(
timestamp=datetime.now(),
model=model,
input_tokens=input_tokens,
output_tokens=output_tokens,
cost=cost,
endpoint=endpoint,
user_id=user_id
)
self.records.append(record)
# Check budget
daily_cost = self.get_daily_cost()
if daily_cost > self.daily_budget * self.alert_threshold:
print(f"WARNING: Daily cost ${daily_cost:.2f} approaching budget ${self.daily_budget:.2f}")
return cost
def get_daily_cost(self, date: datetime = None) -> float:
"""Get total cost for a day."""
date = date or datetime.now()
start = date.replace(hour=0, minute=0, second=0, microsecond=0)
end = start + timedelta(days=1)
return sum(
r.cost for r in self.records
if start <= r.timestamp < end
)
def get_cost_by_model(self, days: int = 7) -> dict[str, float]:
"""Get cost breakdown by model."""
cutoff = datetime.now() - timedelta(days=days)
costs = defaultdict(float)
for r in self.records:
if r.timestamp >= cutoff:
costs[r.model] += r.cost
return dict(costs)
def get_cost_by_endpoint(self, days: int = 7) -> dict[str, float]:
"""Get cost breakdown by endpoint."""
cutoff = datetime.now() - timedelta(days=days)
costs = defaultdict(float)
for r in self.records:
if r.timestamp >= cutoff:
costs[r.endpoint] += r.cost
return dict(costs)
def report(self) -> str:
"""Generate cost report."""
today = self.get_daily_cost()
by_model = self.get_cost_by_model(7)
by_endpoint = self.get_cost_by_endpoint(7)
return f"""
Cost Report
===========
Today: ${today:.4f}
Budget: ${self.daily_budget:.2f} ({today/self.daily_budget*100:.1f}% used)
Last 7 Days by Model:
{json.dumps(by_model, indent=2)}
Last 7 Days by Endpoint:
{json.dumps(by_endpoint, indent=2)}
"""
# Global tracker
tracker = CostTracker()Semantic Caching
Caching dramatically reduces latency and costs by storing and reusing previous results. This implementation includes cache invalidation and TTL management.
import hashlib
import numpy as np
from openai import OpenAI
from typing import Optional
client = OpenAI()
class SemanticCache:
"""Cache responses for semantically similar queries."""
def __init__(
self,
similarity_threshold: float = 0.95,
max_entries: int = 10000,
ttl_hours: int = 24
):
self.threshold = similarity_threshold
self.max_entries = max_entries
self.ttl = timedelta(hours=ttl_hours)
self.cache: dict[str, dict] = {} # hash -> {embedding, response, timestamp}
self.embeddings: list[tuple[str, list[float]]] = [] # (hash, embedding)
def _get_embedding(self, text: str) -> list[float]:
"""Get embedding for cache lookup."""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def _cosine_similarity(self, a: list[float], b: list[float]) -> float:
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def _find_similar(self, embedding: list[float]) -> Optional[str]:
"""Find similar cached query."""
for cache_hash, cache_emb in self.embeddings:
if cache_hash in self.cache:
# Check TTL
if datetime.now() - self.cache[cache_hash]["timestamp"] > self.ttl:
continue
similarity = self._cosine_similarity(embedding, cache_emb)
if similarity >= self.threshold:
return cache_hash
return None
def get(self, query: str) -> Optional[str]:
"""Get cached response for similar query."""
embedding = self._get_embedding(query)
similar_hash = self._find_similar(embedding)
if similar_hash:
return self.cache[similar_hash]["response"]
return None
def set(self, query: str, response: str):
"""Cache a response."""
embedding = self._get_embedding(query)
query_hash = hashlib.md5(query.encode()).hexdigest()
self.cache[query_hash] = {
"response": response,
"timestamp": datetime.now()
}
self.embeddings.append((query_hash, embedding))
# Evict old entries if needed
if len(self.cache) > self.max_entries:
oldest = min(self.cache.items(), key=lambda x: x[1]["timestamp"])
del self.cache[oldest[0]]
self.embeddings = [(h, e) for h, e in self.embeddings if h != oldest[0]]
# Usage with caching
cache = SemanticCache(similarity_threshold=0.92)
def cached_completion(prompt: str, model: str = "gpt-4o") -> str:
"""Get completion with semantic caching."""
# Check cache
cached = cache.get(prompt)
if cached:
print("Cache hit!")
return cached
# Call API
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
# Cache result
cache.set(prompt, result)
# Track cost
tracker.record(model, response.usage.prompt_tokens, response.usage.completion_tokens)
return resultModel Routing
Not every query needs your most powerful model. Intelligent routing classifies requests and sends simple queries to cheaper models while reserving expensive models for complex tasks.
from enum import Enum
class TaskComplexity(Enum):
SIMPLE = "simple" # Formatting, extraction, simple Q&A
MEDIUM = "medium" # Summarization, basic analysis
COMPLEX = "complex" # Reasoning, coding, creative writing
class CostOptimizedRouter:
"""Route requests to appropriate models based on complexity."""
MODEL_MAP = {
TaskComplexity.SIMPLE: "gpt-4o-mini",
TaskComplexity.MEDIUM: "gpt-4o-mini",
TaskComplexity.COMPLEX: "gpt-4o"
}
def __init__(self):
self.classifier_model = "gpt-4o-mini"
def classify_complexity(self, prompt: str) -> TaskComplexity:
"""Classify task complexity."""
# Quick heuristics first
prompt_lower = prompt.lower()
# Simple tasks
simple_indicators = ["format", "extract", "list", "convert", "translate"]
if any(ind in prompt_lower for ind in simple_indicators) and len(prompt) < 500:
return TaskComplexity.SIMPLE
# Complex tasks
complex_indicators = ["analyze", "reason", "code", "debug", "explain why", "compare"]
if any(ind in prompt_lower for ind in complex_indicators) or len(prompt) > 2000:
return TaskComplexity.COMPLEX
return TaskComplexity.MEDIUM
def route(self, prompt: str, force_model: str = None) -> str:
"""Route to appropriate model."""
if force_model:
return force_model
complexity = self.classify_complexity(prompt)
return self.MODEL_MAP[complexity]
def complete(self, prompt: str, force_model: str = None) -> tuple[str, str]:
"""Get completion with automatic routing."""
model = self.route(prompt, force_model)
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
tracker.record(
model,
response.usage.prompt_tokens,
response.usage.completion_tokens
)
return result, model
# Usage
router = CostOptimizedRouter()
# Simple task -> gpt-4o-mini
result, model = router.complete("Format this JSON: {name: 'John', age: 30}")
print(f"Used {model}") # gpt-4o-mini
# Complex task -> gpt-4o
result, model = router.complete("Analyze this code for security vulnerabilities and explain the reasoning...")
print(f"Used {model}") # gpt-4oPrompt Compression
Prompt engineering is critical for getting reliable outputs from LLMs. The following template demonstrates effective prompting patterns.
import tiktoken
class PromptCompressor:
"""Reduce prompt token count while preserving meaning."""
def __init__(self, model: str = "gpt-4o"):
self.encoding = tiktoken.encoding_for_model(model)
def count_tokens(self, text: str) -> int:
"""Count tokens in text."""
return len(self.encoding.encode(text))
def truncate_to_tokens(self, text: str, max_tokens: int) -> str:
"""Truncate text to max tokens."""
tokens = self.encoding.encode(text)
if len(tokens) <= max_tokens:
return text
return self.encoding.decode(tokens[:max_tokens])
def compress_context(
self,
context: str,
max_tokens: int,
preserve_start: int = 500,
preserve_end: int = 500
) -> str:
"""Compress context keeping start and end."""
current_tokens = self.count_tokens(context)
if current_tokens <= max_tokens:
return context
# Keep start and end, summarize middle
start = self.truncate_to_tokens(context, preserve_start)
# Get end portion
tokens = self.encoding.encode(context)
end = self.encoding.decode(tokens[-preserve_end:])
# Calculate remaining budget for middle summary
middle_budget = max_tokens - preserve_start - preserve_end - 50
if middle_budget > 100:
# Summarize middle
middle_start = len(self.encoding.encode(start))
middle_end = len(tokens) - preserve_end
middle = self.encoding.decode(tokens[middle_start:middle_end])
summary_response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{
"role": "user",
"content": f"Summarize in {middle_budget} tokens:\n{middle[:5000]}"
}],
max_tokens=middle_budget
)
middle_summary = summary_response.choices[0].message.content
return f"{start}\n\n[...summarized...]\n{middle_summary}\n\n[...]\n{end}"
return f"{start}\n\n[...truncated...]\n\n{end}"
def remove_redundancy(self, messages: list[dict]) -> list[dict]:
"""Remove redundant content from conversation history."""
compressed = []
seen_content = set()
for msg in messages:
content = msg["content"]
# Hash content to detect duplicates
content_hash = hash(content[:200])
if content_hash not in seen_content:
compressed.append(msg)
seen_content.add(content_hash)
else:
# Keep but truncate duplicate
compressed.append({
"role": msg["role"],
"content": content[:100] + "... [duplicate content removed]"
})
return compressed
# Usage
compressor = PromptCompressor()
# Compress long context
long_document = "..." * 10000 # Very long document
compressed = compressor.compress_context(long_document, max_tokens=4000)
print(f"Original: {compressor.count_tokens(long_document)} tokens")
print(f"Compressed: {compressor.count_tokens(compressed)} tokens")Complete Cost-Optimized Client
The client component handles communication with external services. This implementation includes connection pooling, retry logic, and proper timeout handling.
class OptimizedLLMClient:
"""Production LLM client with all cost optimizations."""
def __init__(
self,
daily_budget: float = 100.0,
cache_threshold: float = 0.92,
enable_routing: bool = True,
enable_caching: bool = True,
enable_compression: bool = True
):
self.client = OpenAI()
self.tracker = CostTracker()
self.tracker.daily_budget = daily_budget
self.enable_routing = enable_routing
self.enable_caching = enable_caching
self.enable_compression = enable_compression
if enable_caching:
self.cache = SemanticCache(similarity_threshold=cache_threshold)
if enable_routing:
self.router = CostOptimizedRouter()
if enable_compression:
self.compressor = PromptCompressor()
def complete(
self,
prompt: str,
model: str = None,
max_tokens: int = 1000,
skip_cache: bool = False
) -> dict:
"""Get completion with all optimizations."""
stats = {
"cache_hit": False,
"model_used": model,
"original_tokens": 0,
"compressed_tokens": 0,
"cost": 0.0
}
# Check cache
if self.enable_caching and not skip_cache:
cached = self.cache.get(prompt)
if cached:
stats["cache_hit"] = True
return {"content": cached, "stats": stats}
# Route to model
if self.enable_routing and not model:
model = self.router.route(prompt)
else:
model = model or "gpt-4o"
stats["model_used"] = model
# Compress if needed
if self.enable_compression:
stats["original_tokens"] = self.compressor.count_tokens(prompt)
if stats["original_tokens"] > 3000:
prompt = self.compressor.compress_context(prompt, max_tokens=3000)
stats["compressed_tokens"] = self.compressor.count_tokens(prompt)
# Call API
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens
)
result = response.choices[0].message.content
# Track cost
stats["cost"] = self.tracker.record(
model,
response.usage.prompt_tokens,
response.usage.completion_tokens
)
# Cache result
if self.enable_caching:
self.cache.set(prompt, result)
return {"content": result, "stats": stats}
def get_cost_report(self) -> str:
return self.tracker.report()
# Usage
llm = OptimizedLLMClient(
daily_budget=50.0,
enable_routing=True,
enable_caching=True
)
# First call - cache miss, routed to appropriate model
result = llm.complete("What is machine learning?")
print(f"Cost: ${result['stats']['cost']:.6f}")
# Similar query - cache hit
result = llm.complete("Explain machine learning")
print(f"Cache hit: {result['stats']['cache_hit']}")
# Check costs
print(llm.get_cost_report())References
- OpenAI Pricing: https://openai.com/pricing
- Anthropic Pricing: https://www.anthropic.com/pricing
- tiktoken: https://github.com/openai/tiktoken
- GPTCache: https://github.com/zilliztech/GPTCache
Conclusion
LLM cost optimization is essential for sustainable production systems. Start with tracking—you can’t optimize what you don’t measure. Implement semantic caching for repetitive queries; even a 20% cache hit rate significantly reduces costs. Use model routing to send simple tasks to cheaper models; GPT-4o-mini handles most formatting and extraction tasks well at 1/15th the cost of GPT-4o. Compress long contexts to reduce token counts. Combine these techniques for multiplicative savings. Monitor daily costs and set alerts before hitting budget limits. The goal isn’t minimum cost—it’s optimal cost-to-quality ratio. Some tasks genuinely need expensive models, and that’s fine. The savings from optimizing routine tasks fund the premium calls that matter.
Key Takeaways
- ✅ Route by complexity – Use cheap models for simple queries
- ✅ Minimize tokens – Compress prompts and responses without losing quality
- ✅ Cache aggressively – Semantic caching provides 50%+ savings
- ✅ Set budgets and alerts – Prevent runaway costs with hard limits
- ✅ Track cost per feature – Know where money goes to optimize effectively
Conclusion
LLM costs can quickly become significant, but thoughtful optimization—model routing, token reduction, caching, and budget management—can reduce spend by 50-80% without impacting quality.
References
Discover more from C4: Container, Code, Cloud & Context
Subscribe to get the latest posts sent to your email.